Decompiling 2024: A Year of Resurgence in Decompilation Research
TL;DR
The year 2024 was a resurgent year for decompilation. Academic publications from that year made up nearly 30% of all top publications ever made in decompilation. In this post, I do a summarization and retrospective of both the academic and ideological progress of decompilation in 2024. Hint: decompilation research is back.Looking Back on 2024
Last year, I kicked off 2024 by paying tribute to the last 30 years of decompilation research, where I summarized work in control flow structuring. As 2025 has come along, it only feels right to do a similar post, but instead on a tighter scope of the field’s growth in 2024 alone. Though this field is still small, it feels like it is growing rapidly. 2024 featured a talk tour by the decompilation pioneer Dr. Cristina Cifuentes, a world-renowned decompilation panel at Recon 2024, and the highest top-tier publication record in history for decompilation.
For me, 2024 was filled with lots of travel and new colleagues. Many of these new colleagues are decompilation practitioners, rising experts, and even bonafide field pioneers. They reign from academia and industry alike, and many have their own vision for where they believe this field is going. However, there is a unifying trend in vibes: decompilation research is back.
A Surge in Academic Work
Academia, publications, and graphs don’t always tell the whole truth about a field, but it’s a great place to start. The graph below shows the number of decompilation works published in academic venues since 1993 (the earliest academic work).
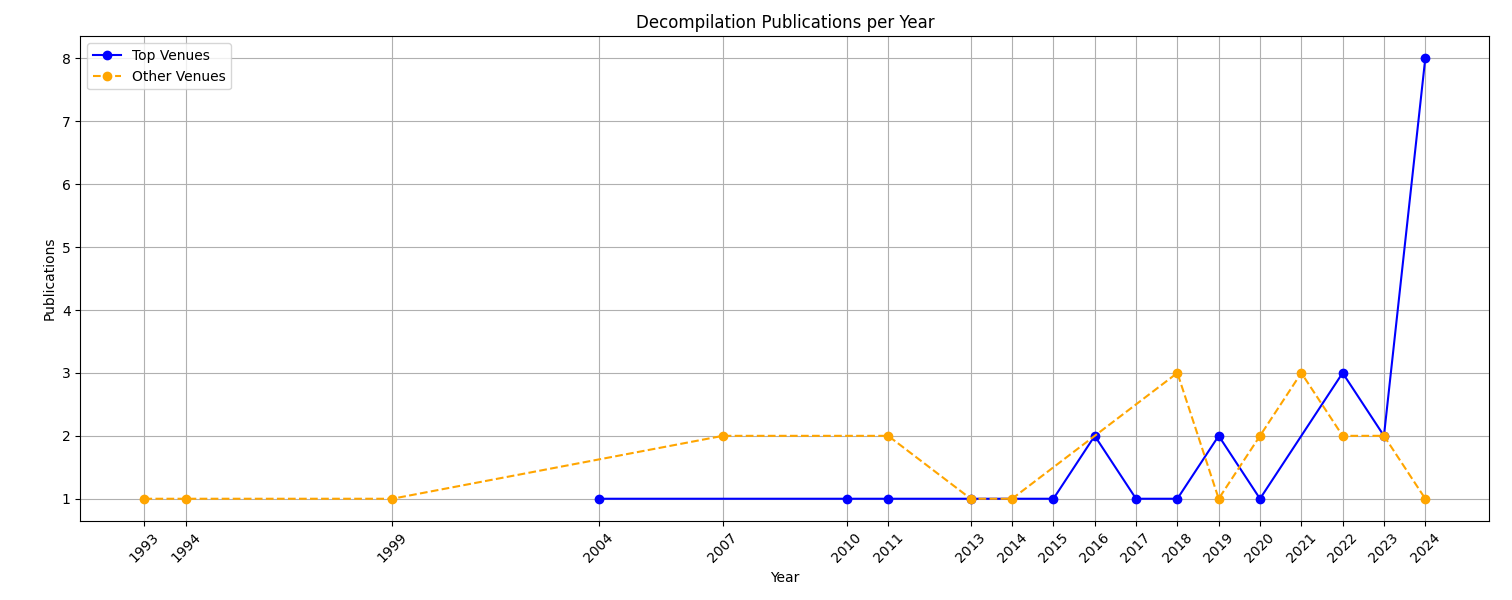
The graph data is sourced from my list of decompilation works made for the Decompilation Wiki. It includes nearly every paper from software engineering, programming languages, and security conferences published from 1970 onwards. The papers graphed above are exclusively works in decompilation, as opposed to works in compilation that contributed to decompilation (see sheet for more info).
Starting in 2011, the total number of top-tier published papers (as defined by csrankings) was 25. Amazingly, 30% of all top-tier work was published in 2024, 8 papers in total. It’s hard to claim line trends with such a small dataset (usually one paper a year), but 2024 is clearly out of place. 2024 more than doubled the total top publications in 2022, which had also doubled 2020.
Interestingly, we also see a trend of the top vs low-tier publications for academics. Decompilation has traditionally been saturated in non-top-tier conferences. It’s hard to know why, but I speculate it’s due to decompilations’ difficulty to publish in top conferences. However, we’ve recently seen top publications close to or exceed non-top publications in quantity.
This data indicates two things to me:
- Decompilation is now mature enough to publish in top-tier
- Decompilation is growing rapidly
This is great news, but is field health just about quantity? What about quality? Well, let’s take a closer look at three emerging trends from the eight works published in 2024.
Trend 1: Defining “Good” Decompilation
Often, decompiler enthusiasts argue about what the “best” decompilation looks like, primarily with no good answer. Luckily, four of the eight new works measured and defined what good decompilation should look like. These studies were both automated and human-driven and often defined new ways to improve decompilation for the future. Take, for instance, the work from Dramko et al. on studying “Decompiler Fidelity Issues”, pictured below.

His work took the gracious time to define what exactly is wrong with decompilation manually. To the savvy decompiler user, this may seem like a grouping of well-known problems. However, this work establishes a precedent: good decompilation looks like its source. Interestingly, this work’s claim coincides with work published simultaneously, SAILR (my work). SAILR, extended this manual effort by introducing an automated algorithm for finding mismatches in source and decompilation and improving those locations, which may find itself in Ghidra soon. Both work towards making decompilation like source.
On the other end of the spectrum, one work, R2I, defined good decompilation as being simple, much like previous work. They focus on finding the best decompilation by comparing decompilers against each other. Finally, the last work defined good decompilation as being semantically accurate. The work D-Helix used symbolic execution to verify if decompilation was like its source, finding actual bugs in decompilers.
To keep count, 2 vote source code recovery, 1 vote simple code recovery, and 1 vote semantically correct. These works open the door for continued development and publication in decompilation research.
Trend 2: AIxDecompilation is Here to Stay
If you’ve ever talked to me in person, you’d know that I’m a disbeliever of AI replacing decompilers any time soon. However, 2024 research has made it clear that AI has a real place in improving specific tasks in decompilation. There were four works utilizing AI in 2024, working on symbol prediction, type prediction, and overall code simplification.
LLMs made their debut in decompilation in two works: DeGPT and ReSym. Both utilized LLMs to recover variable names, structures, types, and, in the case of DeGPT, code simplification (though very limited). Other works used more traditional models to do singular tasks. VarBERT utilized a BERT model to predict variable names, while TyGr utilized a GNN to predict structures and variable types.
Here are some of the inspiring results of structure recovery from AI works (ReSym shown below):

These works resulted in a strict improvement over traditional decompilation, which almost always lacks types and symbols. It’ll be interesting to see if these approaches can improve with bigger models (coughs in o1) and how much of the fundamental components in decompilers can be replaced. I think it will only get better from here.
Trend 3: Theory comes with Application
I often feel that industry looks down on academia because we frequently have unusable inventions and theories. Being a mainly applied science, decompilation must be the exception to these expectations, and luckily, it was in 2024.
In all but 1, each 2024 paper came with an open-source implementation. Many of those implementations had working tools that could be integrated into real-world decompilers and techniques. Considering that back in 2011, none of the decompilation works were open-source, this is a massive step in the right direction.
This trend allows the industry to gain usefulness from work in decompilation research more rapidly, making it more valuable. Additionally, it makes it easier for new researchers to quickly understand flaws in previous work and look for new directions. I encourage others to make usable and open-source implementations of their epic works so we can all nerd out together about them.
Other Researchers and Conferences
Aside from direct academic publishing, many other things flourished this year for decompilation. There were big updates for big decompilers, fundamental changes for smaller ones, new industry approaches in full-AI decompilers, and some great talks across the cons. I’d also like to acknowledge all the unpublished researchers who showed me really cool things in 2024, like a DSL for decompilation.
For most of 2024, Dr. Cristina Cifuentes (the academic pioneer of decompilers) toured the world, giving talks on her work in shaping the last 30 years of research. From my perspective, this peaked when she gave the keynote at Recon 2024. The announcement of her talk set off a flurry of talk proposals on decompilation at Recon, totaling five talks involving decompilation and including a decompilation expert panel.
The panel, consisting of industry and academic experts, was epic, to say the least. To name a few, it included:
- Dr. Sergey Bratus, a previous DARPA PM and kickstarter of significant DoD investment in decompilation
- Ilfak Guilfanov, the creator of IDA Pro
- Rusty Wagner, the man behind some of the biggest changes in Binary Ninja
Dr. Cifuentes grilled each panel member to give their honest opinions on the future of decompilation. Many said, “There is more to do and more breakthroughs to be had.” One such panel member, Ilfak, the current king of decompilers, said otherwise but admitted that breaking a decompiler was as easy as “breaking a baby.” To summarize, it was a meeting of legends that inspired the community to keep pushing.
Note: no babies were harmed in the making of these decompilers.
Concluding
With the trend of publications, new findings, and general expert vibes, I can only conclude that 2024 was a special year for decompilation. This is the field’s most active year since its inception in the 90s. I remain optimistic that it is only the beginning of the research that will come in decompilation. That also makes 2025 a spectacular year to ride the new excitement in the field and do great research, both from new and old researchers.
If you are a rising expert (or a zany practitioner), I encourage you to contribute your knowledge to the Decompilation Wiki so it may continue to organize and guide the field. Additionally, if you have any smaller research in decompilers you think is neat, consider following me on some social media, where announcements for a new decompilation workshop may come. The conference to be co-located at is still being discussed, but I’m actively looking to gauge interest from the community.
Finally, I’d like to acknowledge Dustin Fraze for his work on DARPA’s CHESS program, which funded and made many of this research possible. He also reports bugs in decompilers a lot… ha! Thank you for reading and joining me on this journey through decompilation. Here’s to 2024 and the exciting research to come in 2025!